1. Mở đầu: Giới hạn của mạng nơ-ron truyền thống
Các mạng nơ-ron lan truyền tiến (feedforward neural networks – FNNs) đã chứng minh tính hiệu quả trên dữ liệu dạng vector. Tuy nhiên, khi áp dụng vào dữ liệu ảnh – vốn có cấu trúc không gian hai chiều (hoặc ba chiều nếu tính cả màu) – các mạng fully connected bộc lộ nhiều điểm yếu:
- Số lượng tham số cực lớn: Ảnh 256×256×3 có tới gần 200.000 pixel → hàng triệu trọng số nếu kết nối toàn bộ.
- Bỏ qua tính cục bộ: Quan hệ giữa các pixel lân cận – yếu tố quan trọng trong ảnh – bị làm phẳng và mất ý nghĩa không gian.
- Không khai thác tính bất biến: Mô hình không nhận ra rằng một vật thể vẫn là nó dù nằm ở vị trí khác nhau trong ảnh.
Để vượt qua những hạn chế này, một kiến trúc mới được thiết kế riêng cho dữ liệu hình ảnh – Convolutional Neural Networks (CNNs) – được đề xuất và phát triển mạnh mẽ từ cuối thập niên 1980 (LeNet, Yann LeCun), và trở thành chuẩn mực từ sau chiến thắng của AlexNet (2012) tại ImageNet.
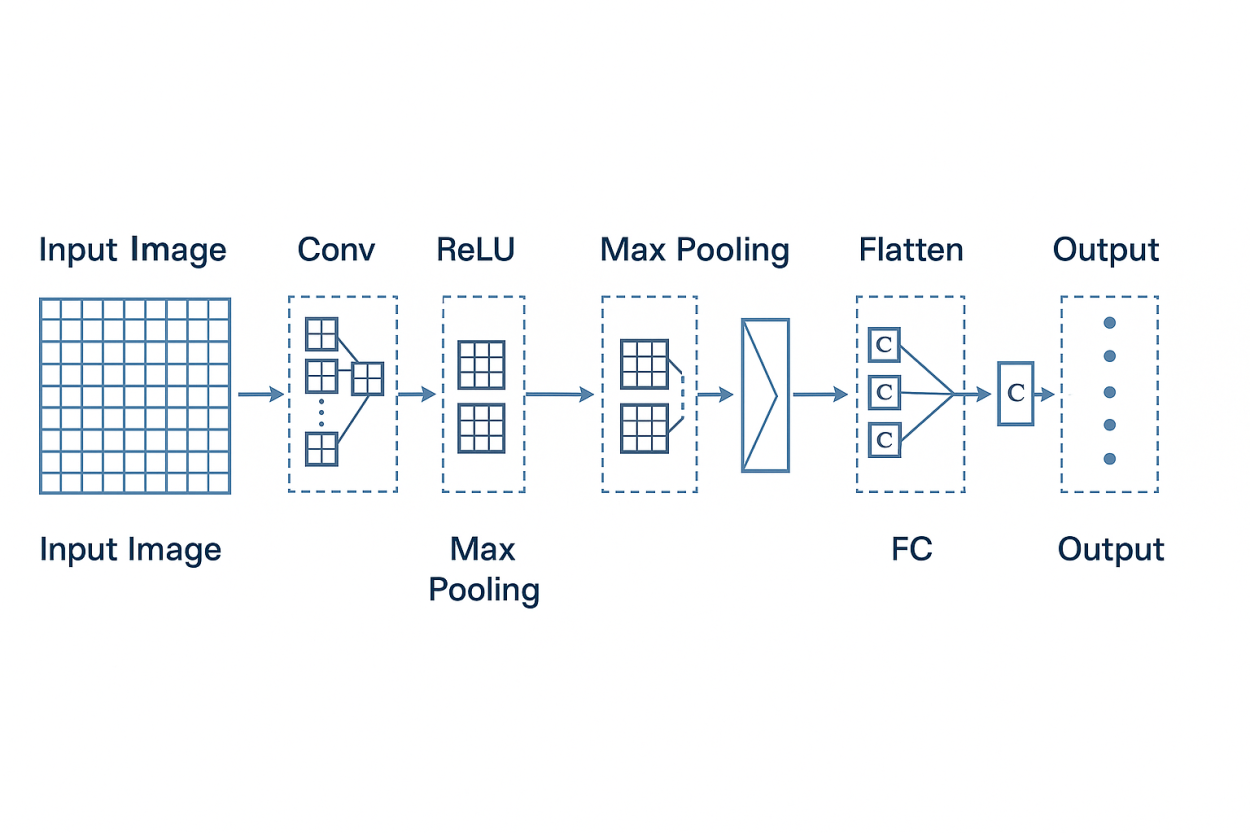
2. CNN là gì?
Convolutional Neural Network (CNN) là một loại mạng nơ-ron đặc biệt có khả năng:
- Xử lý dữ liệu có cấu trúc không gian (spatial structure) như ảnh, video.
- Tự động học biểu diễn đặc trưng (feature representation) ở nhiều cấp độ: từ mép cạnh đến vật thể.
- Hạn chế số lượng tham số nhờ vào chia sẻ trọng số (weight sharing) và liên kết cục bộ (local connectivity).
Khác với FNN, CNN sử dụng các khối (blocks) đặc biệt thay cho lớp fully connected, trong đó quan trọng nhất là:
- Lớp tích chập (Convolutional layer)
- Lớp phi tuyến (Non-linearity layer – thường là ReLU)
- Lớp gộp (Pooling layer)
- Lớp chuẩn hóa (Normalization layer – tuỳ biến)
- Lớp kết nối đầy đủ (Fully connected layer)
3. Tích chập (Convolution): Cốt lõi toán học của CNN
3.1 Định nghĩa toán học
Cho một ảnh đầu vào I∈RH×W, và một kernel K∈Rk×k, phép tích chập (I∗K)(i,j) được tính như sau:(I∗K)(i,j)=∑m=0k−1∑n=0k−1K[m,n]⋅I[i+m,j+n]
- Ảnh đầu vào: ma trận pixel
- Kernel (hoặc filter): ma trận nhỏ trượt trên ảnh
- Đầu ra: ảnh mới gọi là feature map
3.2 Ý nghĩa trực giác
Kernel hoạt động như “mắt quét” học các đặc trưng cục bộ như cạnh, góc, hình dạng. Trong quá trình huấn luyện, các giá trị trong kernel không cố định mà được cập nhật qua backpropagation.
Mỗi kernel học một loại đặc trưng khác nhau. Ví dụ:
- Một kernel học cách phát hiện cạnh ngang
- Một kernel khác phát hiện vùng sáng → tối
Kết quả: mô hình tự học cách nhận biết đặc trưng từ thấp đến cao.
4. Các lớp chính trong kiến trúc CNN
4.1 Convolutional Layer
- Input: ảnh hoặc feature map (tensor 3 chiều: H×W×C)
- Tham số học: các kernel, thường kích thước 3×3, 5×5
- Output: tập hợp các feature map
Tổng số tham số: k×k×Cin×Cout
→ Rất nhỏ so với fully connected.
4.2 ReLU Layer (Non-linearity)
- Hàm kích hoạt phi tuyến: ReLU(x)=max(0,x)
- Tăng tính mô hình hóa phi tuyến
- Trực quan: loại bỏ giá trị âm, giữ lại tín hiệu tích cực
4.3 Pooling Layer (Subsampling)
- Giảm kích thước không gian, giữ thông tin chính
- MaxPooling là phổ biến nhất:
- Chọn giá trị lớn nhất trong mỗi vùng nhỏ (thường 2×2)
- Góp phần tạo bất biến dịch chuyển (translation invariance)
4.4 Fully Connected Layer
- Hoạt động giống như trong FNN
- Nhận đầu vào từ các feature map đã được flatten
- Thường dùng cho các tác vụ phân loại, dự đoán
5. Cấu trúc CNN điển hình
Ví dụ kiến trúc xử lý ảnh 28×28 (ảnh chữ số viết tay – MNIST):
Input: 28×28×1
→ Conv(3×3, 16 filters) → ReLU
→ MaxPooling(2×2)
→ Conv(3×3, 32 filters) → ReLU
→ MaxPooling(2×2)
→ Flatten
→ FC(128) → ReLU
→ FC(10) → Softmax
Tổng cộng có 2 lớp tích chập, 2 lớp gộp, 2 lớp fully connected.
Mỗi bước giúp trích xuất đặc trưng ngày càng trừu tượng hơn.
6. Phân biệt CNN với Fully Connected NN
| Đặc điểm | Fully Connected NN | CNN |
|---|---|---|
| Kết nối | Mỗi node nối với toàn bộ | Chỉ nối cục bộ (local) |
| Trọng số | Mỗi kết nối có trọng số riêng | Các kernel chia sẻ trọng số |
| Phù hợp | Dữ liệu vector | Dữ liệu ảnh, tín hiệu |
| Tham số | Rất lớn | Giảm mạnh (vài chục lần) |
| Biểu diễn | Học toàn cục | Học từ cục bộ → toàn cục |
7. Ứng dụng CNN trong thực tế
- Phân loại ảnh: ImageNet, CIFAR-10, MNIST
- Nhận diện khuôn mặt: FaceNet, DeepFace
- Phân đoạn ảnh y tế: U-Net
- Tự lái xe: Phân tích hình ảnh từ camera
- Phát hiện vật thể: YOLO, Faster R-CNN
- Chuyển phong cách ảnh: Style Transfer (Gatys et al.)
8. CNN và tính bất biến
Một đặc tính mạnh của CNN là:
- Bất biến dịch chuyển: một vật thể vẫn được nhận diện dù xuất hiện ở vị trí khác nhau
- Khả năng khái quát mạnh: nhờ học trích xuất đặc trưng có tính phân cấp
Điều này đến từ:
- Việc sử dụng kernel (nhận diện theo vùng)
- Pooling (làm mờ vị trí cụ thể)
- Tăng dữ liệu (data augmentation)
9. Kết luận
Mạng tích chập CNN là công cụ cốt lõi của thị giác máy tính hiện đại. Chúng tận dụng cấu trúc không gian của ảnh để học đặc trưng một cách hiệu quả, giảm số lượng tham số, và tăng khả năng tổng quát. Việc hiểu rõ từng thành phần – tích chập, kích hoạt, gộp, kết nối – là điều kiện tiên quyết để có thể xây dựng và tinh chỉnh các mô hình xử lý ảnh thực tế.
Gợi ý tiếp theo
- Bài 5: Xây dựng mô hình CNN đầu tiên với PyTorch trên tập MNIST
- Bài 5 mở rộng: Visualize kernel, feature map – “CNN nhìn gì?”
- Bài 6: Các kỹ thuật cải tiến CNN – Dropout, BatchNorm, Data Augmentation
Leave a Comment